By A Mystery Man Writer
🐛 Bug Using DistributedDataParallel on a model that has at-least one non-floating point dtype parameter with requires_grad=False with a WORLD_SIZE <= nGPUs/2 on the machine results in an error "Only Tensors of floating point dtype can re

Error Message RuntimeError: connect() timed out Displayed in Logs_ModelArts_Troubleshooting_Training Jobs_GPU Issues

Distributed PyTorch Modelling, Model Optimization, and Deployment

Number formats commonly used for DNN training and inference. Fixed
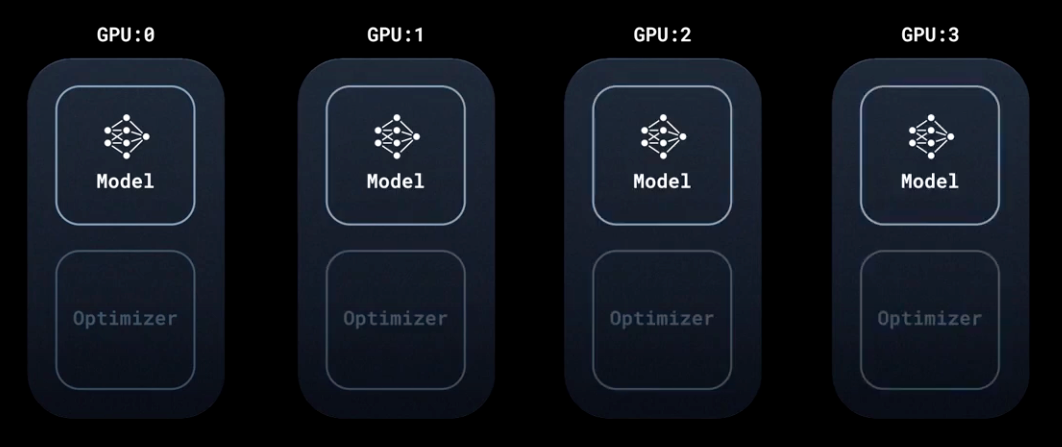
A comprehensive guide of Distributed Data Parallel (DDP), by François Porcher
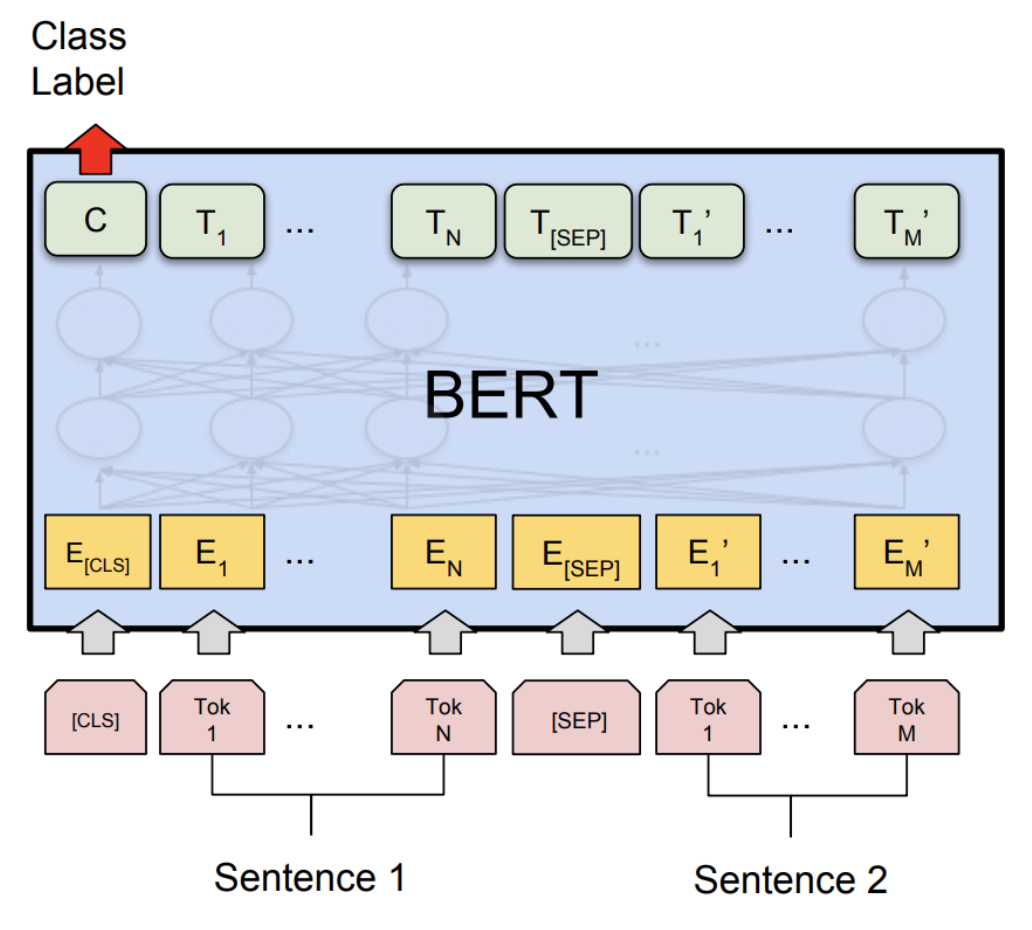
beta) Dynamic Quantization on BERT — PyTorch Tutorials 2.2.1+cu121 documentation

torch.nn、(一)_51CTO博客_torch.nn
torch.utils.tensorboard — PyTorch 2.2 documentation
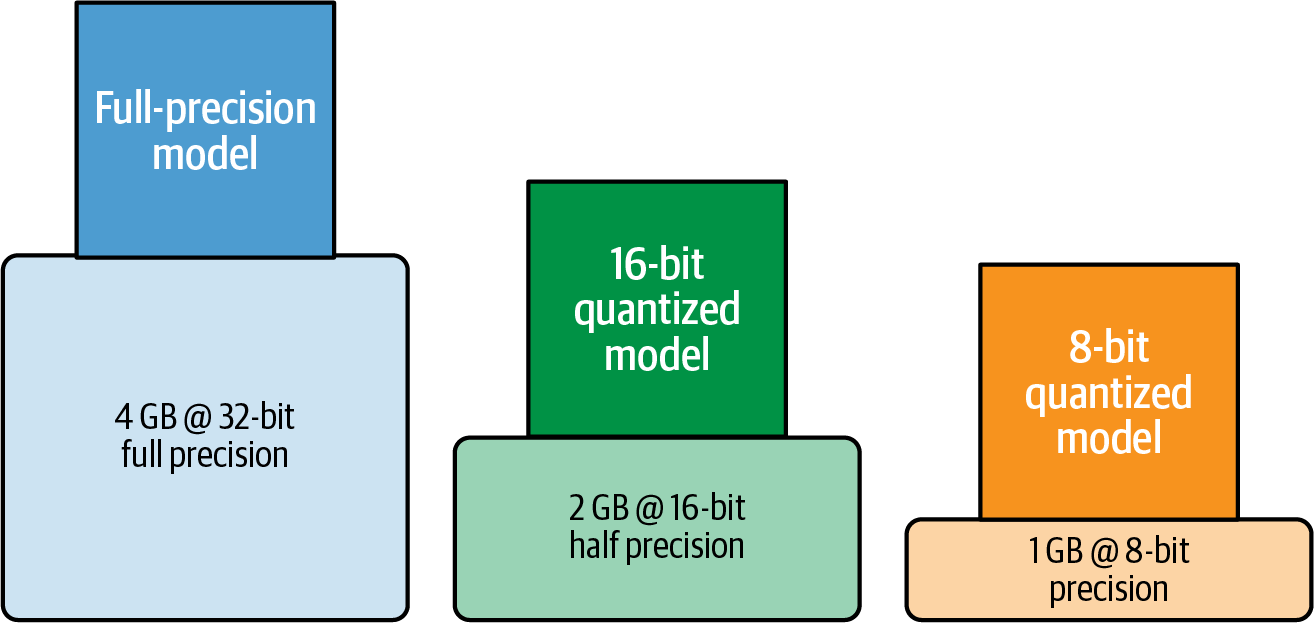
4. Memory and Compute Optimizations - Generative AI on AWS [Book]
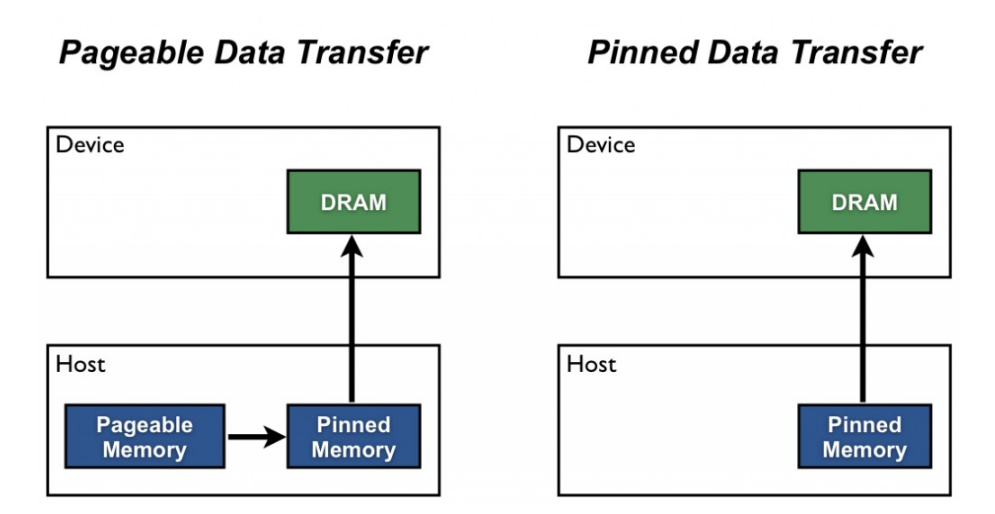
Optimizing model performance, Cibin John Joseph
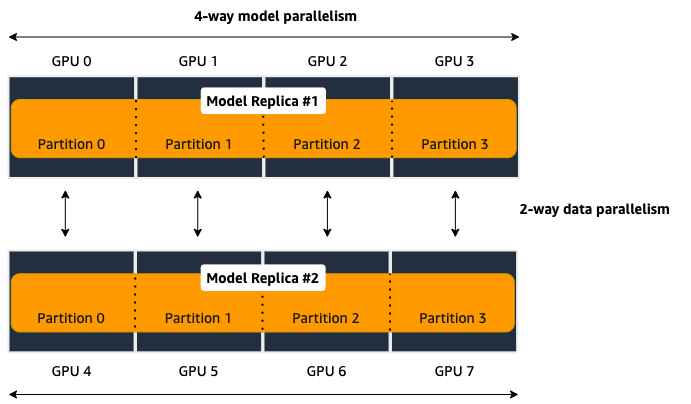
Run a Distributed Training Job Using the SageMaker Python SDK — sagemaker 2.113.0 documentation

Performance and Scalability: How To Fit a Bigger Model and Train It Faster
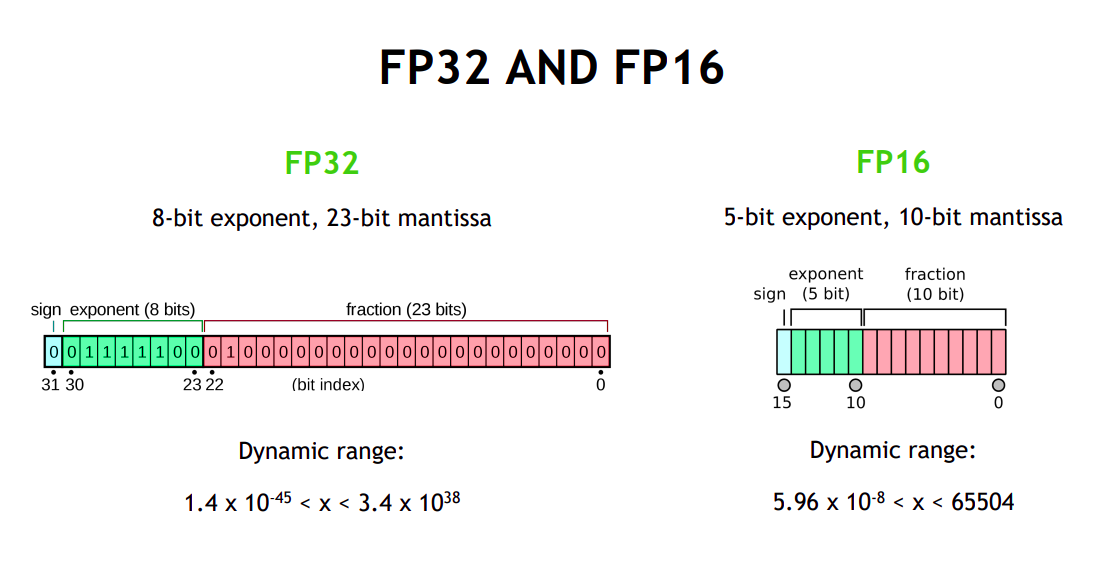
Optimizing model performance, Cibin John Joseph

PyTorch Numeric Suite Tutorial — PyTorch Tutorials 2.2.1+cu121 documentation
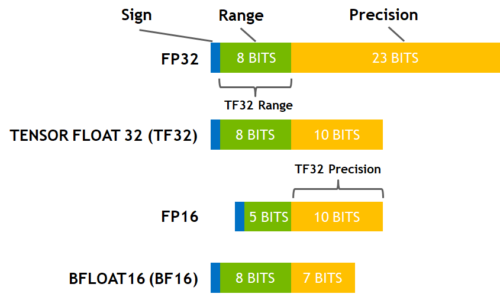
Performance and Scalability: How To Fit a Bigger Model and Train It Faster