By A Mystery Man Writer


PDF) oBERTa: Improving Sparse Transfer Learning via improved initialization, distillation, and pruning regimes
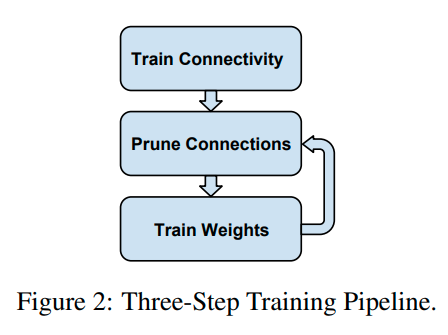
Neural Network Pruning Explained
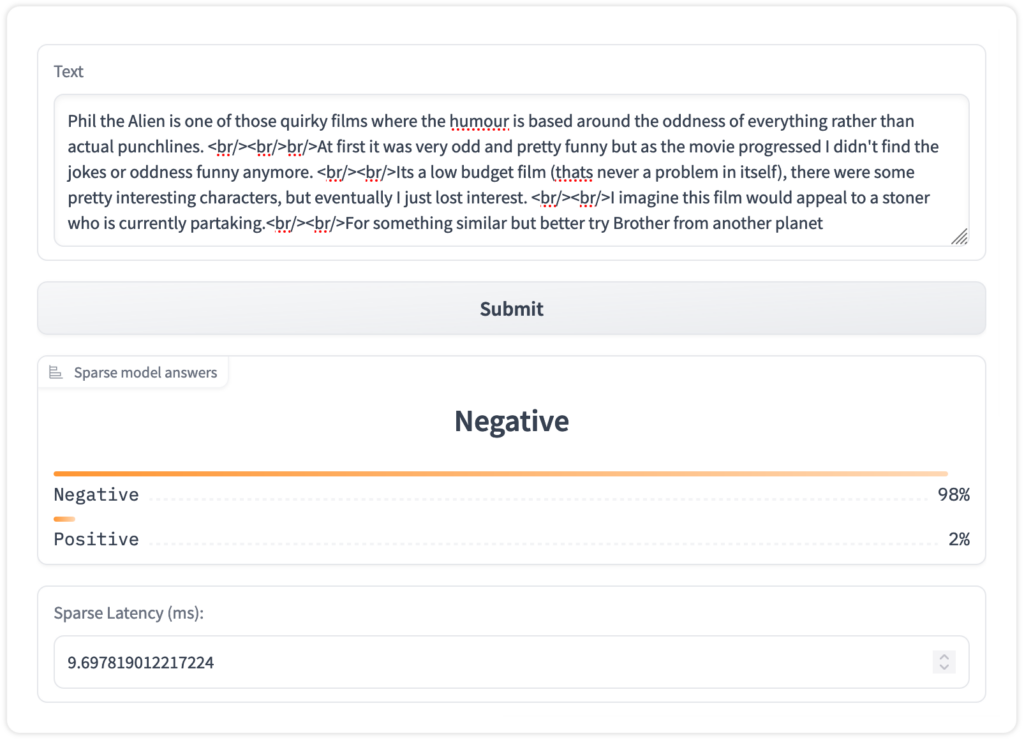
Deploy Optimized Hugging Face Models With DeepSparse and SparseZoo - Neural Magic

Moshe Wasserblat on LinkedIn: BERT-Large: Prune Once for DistilBERT Inference Performance

PDF) Prune Once for All: Sparse Pre-Trained Language Models

PDF) The Optimal BERT Surgeon: Scalable and Accurate Second-Order Pruning for Large Language Models

Guy Boudoukh - CatalyzeX

PDF) Sparse*BERT: Sparse Models are Robust

arxiv-sanity

Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF