By A Mystery Man Writer

Compress BERT-Large with pruning & quantization to create a version that maintains accuracy while beating baseline DistilBERT performance & compression metrics.
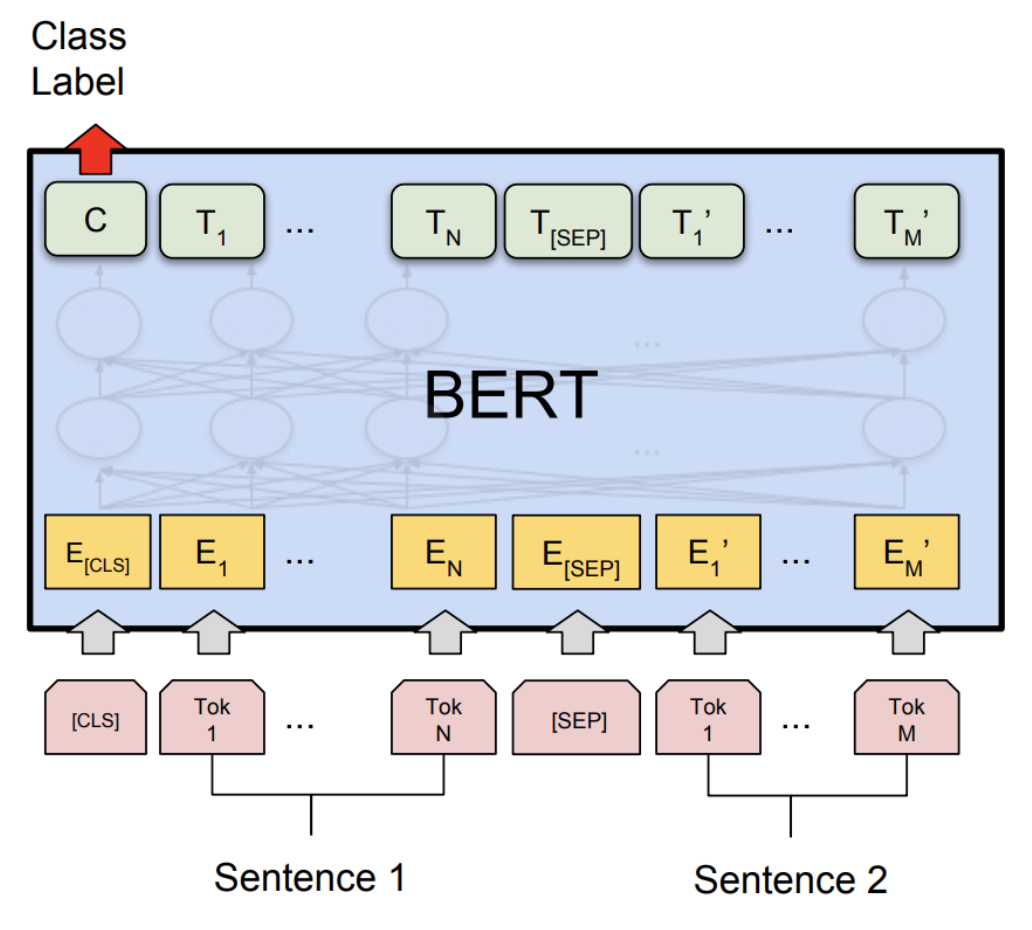
beta) Dynamic Quantization on BERT — PyTorch Tutorials 2.2.1+cu121 documentation

Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF

Understanding Distil BERT In Depth, by Arun Mohan

Dipankar Das on LinkedIn: Intel Xeon is all you need for AI

Excluding Nodes Bug In · Issue #966 · Xilinx/Vitis-AI ·, 57% OFF

Know what you don't need: Single-Shot Meta-Pruning for attention heads - ScienceDirect

Delaunay Triangulation Mountainscapes : r/generative
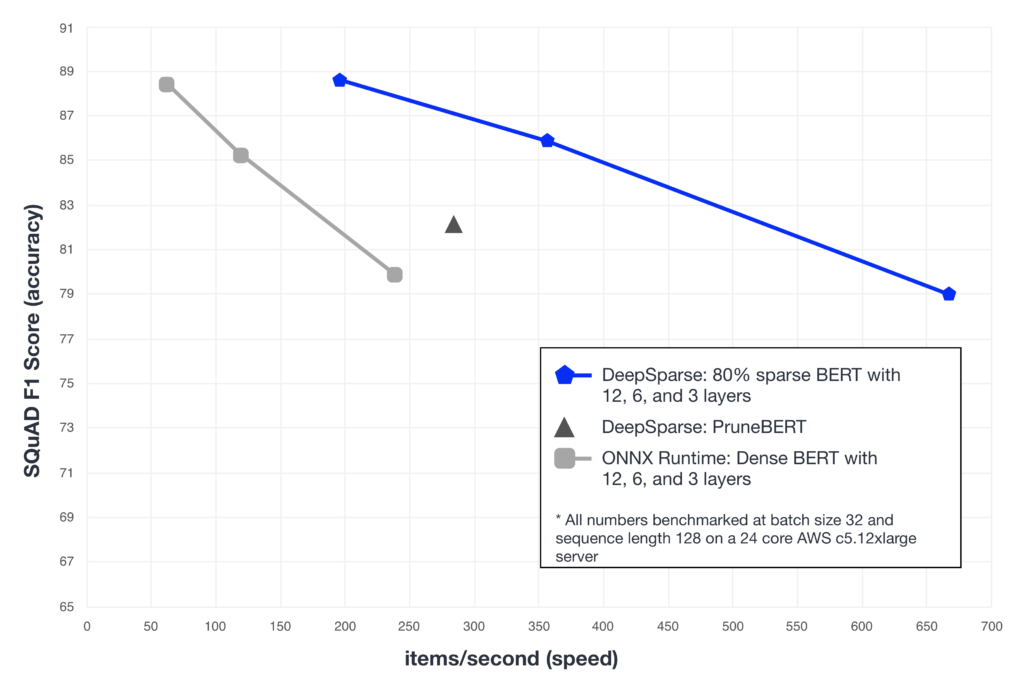
Pruning Hugging Face BERT with Compound Sparsification - Neural Magic

PDF] Prune Once for All: Sparse Pre-Trained Language Models

Qtile and Qtile-Extras] Catppuccin - Arch / Ubuntu : r/unixporn